反向传播 Backpropagation
Regularization
为了防止过拟合(overfitting),我们经常会在loss function里加一项egularization term(正则化项),用来惩罚过大的模型参数,使模型不要过度依赖训练数据中的某些特征。
一般有2种:
L1 Regularization会鼓励权重稀疏,也就是会倾向于将权重集中在少数特征上。
L2 Regularization会鼓励权重变小且更平滑,倾向于将权重分散到多个特征上。
来看个例子:
会发现:
可以从2个角度来理解这个区别:
1. 导数:
L1的导数:
在Gradient Descent(梯度下降法)里的更新就是:
也就是每个component挪动的距离都是一样的(只和$w_i$的正负有关,与大小无关),而且是都往0点的方向移动。所以原本偏小的component就很容易趋近0,导致最后非常少的component不等于0。
L2的导数:
在Gradient Descent(梯度下降法)里的更新就是:
也就是按比例缩小权重。
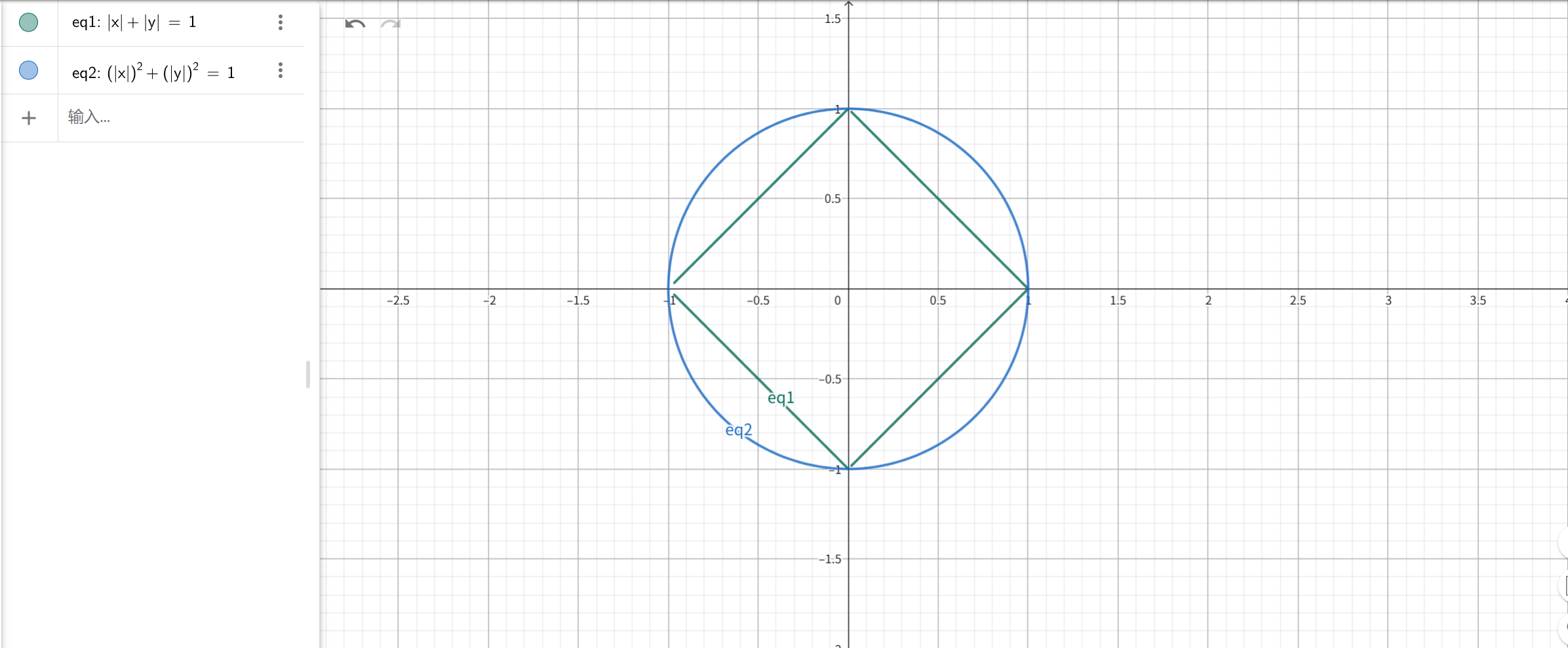
2. 单位圆
观察L1和L2的单位圆不能发现:
- L1 norm的在2维里是一个菱形,在高维里是一个有很多尖角的多面体。所以最优解容易落在某一个尖角上(也就是部分权重等于0)。
- L2 norm的是一个圆形,在高维里是球,是光滑的,所以最优解的权重分布比较平均。