
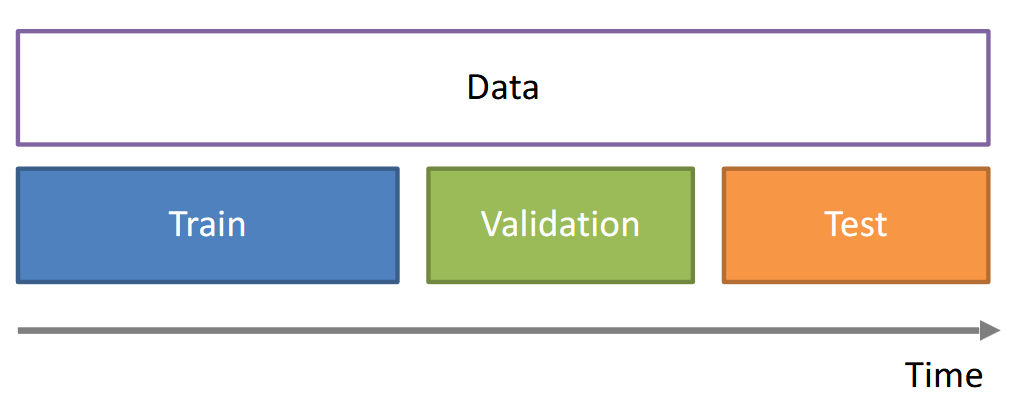
Sequential Data / Temporal Data
针对Sequential Data我们一般会这样划分机器学习的数据集,只用未来的数据进行测试:
Autoregressive Models
Motivation & Definitions
Motivation: 很多时间序列都有这种特点:
- 今天气温和昨天气温接近
- 今天销量会受前几天销量影响
- 今天利率、通胀、库存、流量,通常和前几天的数据有关系
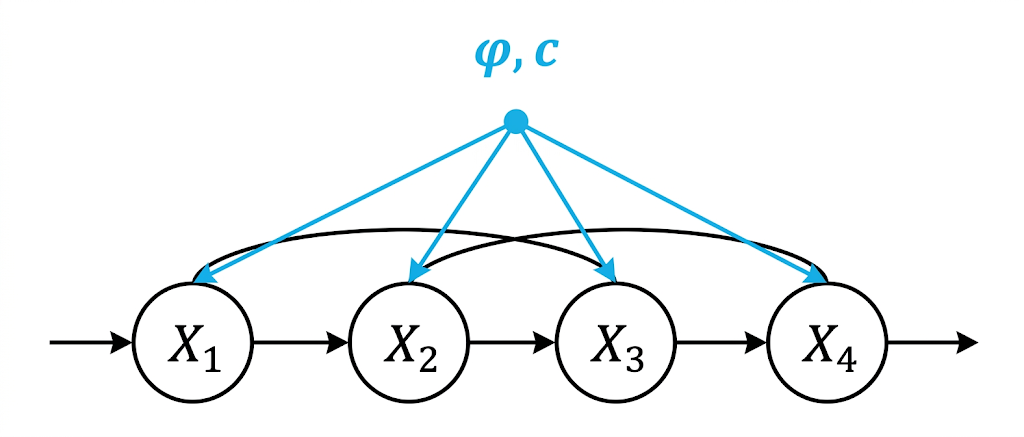
所以就有了以下定义的 autoregressive model:
Definition: An autoregressive model AR(p) of order $p$ is defined as
where $\varphi_1, \ldots, \varphi_p$ are the parameters, $c$ is a constant, and $\varepsilon_t \sim N(0,\sigma)$ is white noise. The variable $X_{t-i}$ is the lagged value of $X$ at time $t-i$.
也可以写成:
注意,随着t增加,$\varphi_i$不变,但是会跟着一起”平移“:
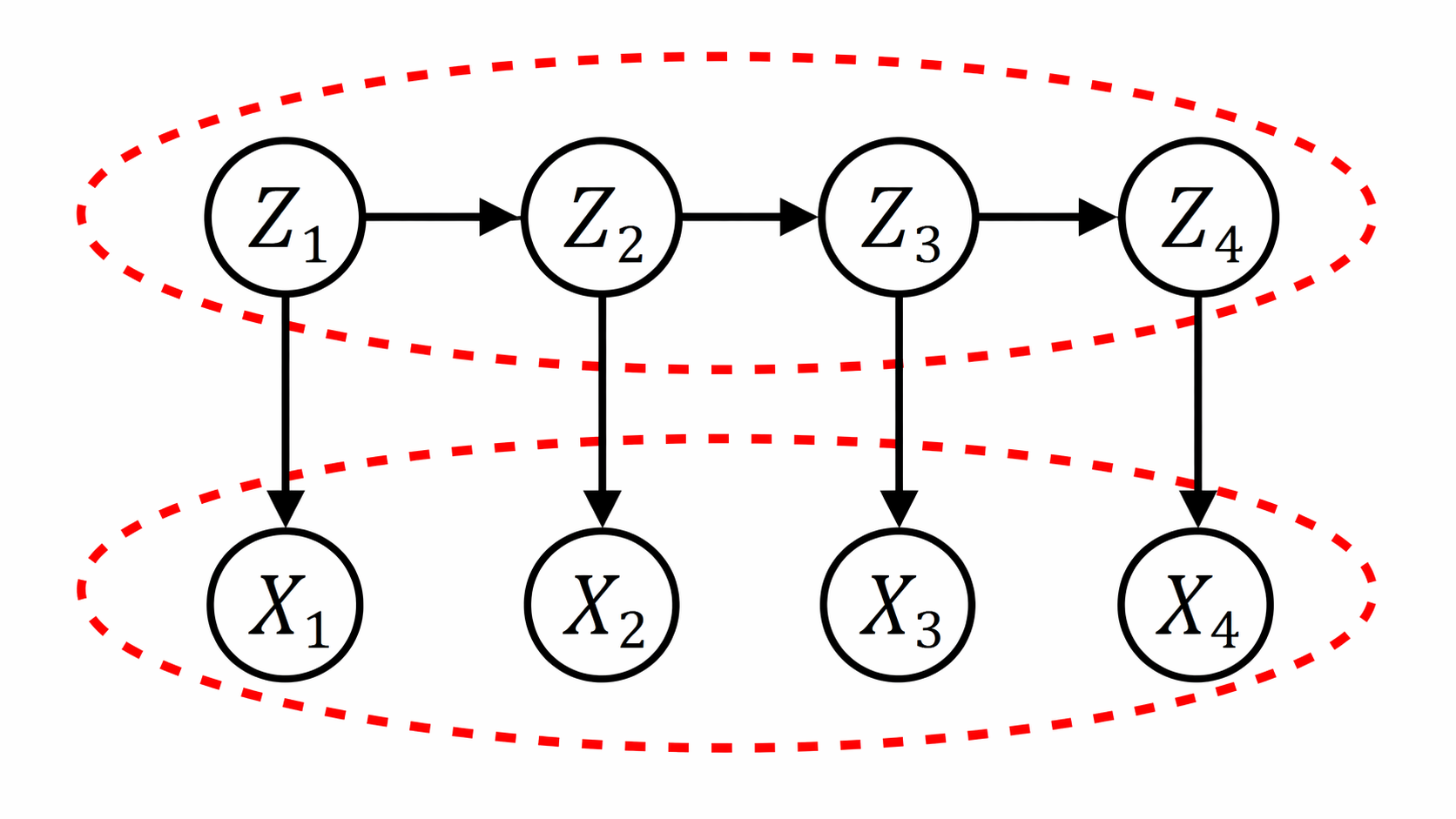
对应的Graphical Model:
Definition:
The mean function of an AR model is $\mu(t) = E[X_t]$.
By default, it depends on $t$.The autocovariance is $\gamma(t,i) = \operatorname{Cov}(X_t, X_{t-i})$.
By default, it depends on $t$ and $i$.The autocovariance function can be normalized to give the Pearson autocorrelation function
It lies in $[-1,1]$.
参数学习(Parameter learning)
先假设$c=0$,不难发现对 $t = p, p+1, p+2, \ldots, T$,分别有::
写成矩阵的形式就是:
记成:
用OLS(ordinary least squares)的公式可得:
如果$c$不等于0的话,把$X$和$\varphi$调整成:
再套用公式即可。
Stationary
Definition:
A process is said to be stationary if
1.$E[X_t] = E[X_{t-i}] = \mu,\ \forall\ t,\forall\ i$(也就是$E[X_t] \equiv \mu \ \forall t$)
2. $\text{Cov}(X_t, X_{t-i}) = \gamma_i,\ \forall\ t,\forall\ i$
3. $E\left[|X_t|^2\right] < \infty,\ \forall\ t$
Theorem: Consider the stationary AR$(p)$ process
with $\epsilon \sim \mathcal{N}(0,\sigma^2)$. Then:
Proof:
1.
2,3.
因为$\epsilon_t,\epsilon_{t-i}$之间是independent,所以$\epsilon_t$也和之前的$X_{t-i}$是independent的:
从而得到
$\square$
在满足stationary的条件下,我们可以用Yule-Walker equations来学习参数:
Yule-Walker equations:
因为
所以这里的Yule-Walker矩阵也可以写成对称的形式:
具体流程:
1. 计算协方差$\gamma_0,…,\gamma_p$:
先估计均值:
然后用样本自协方差估计 moments:
2. 计算Yule_Walker矩阵的逆,解得$\varphi_1,…,\varphi_p$ (解方程)
3. 利用$\gamma_0$的公式来estimate $\sigma$:
注意到其实Yule-Walker矩阵本质上是一个协方差矩阵,假设
那么
Markov Chains
我们假设r.v $X_t$和time index都是离散的。
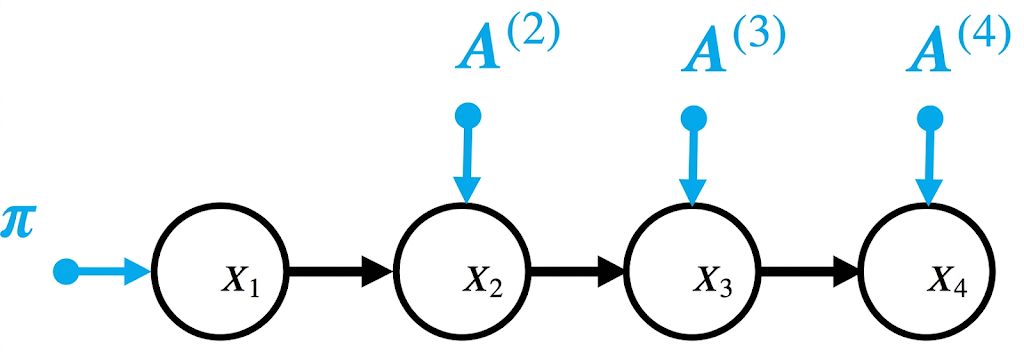
Definition: A Markov Chain is a sequence of r.v. $X_1, X_2, \ldots, X_T$ which fulfills the Markov property:
也就是说,当前状态出现的概率只取决于上一个状态。
Joint distribution则是:
General的情况下,每个r.v的分布可能是不同的,也就是说
here $\pi \in \mathbb{R}^K$ is a prior probability on the initial state, and $A^{(t)} \in \mathbb{R}^{K \times K}$ are the transition matrices.
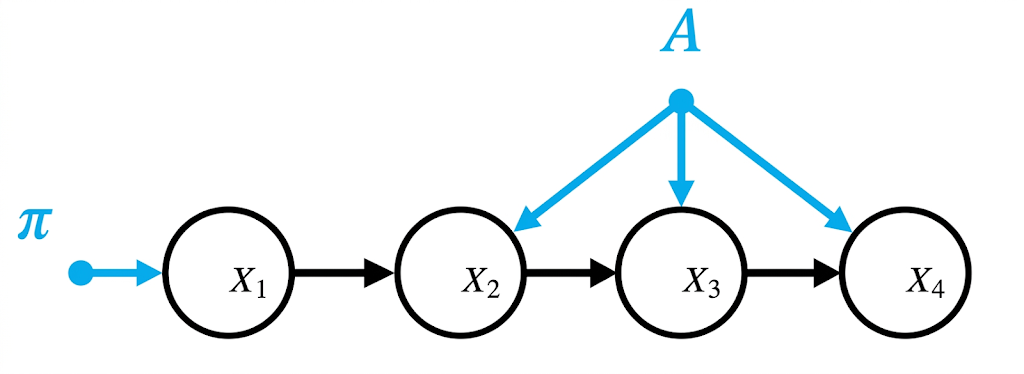
但是我们这里考虑简单点的情况:time-homogeneous / stationary Markov Chain
也就是$A^{(t)} \equiv A \ \forall t$。
Theorem:
Theorem:
参数学习(Parameter learning)
核心思路就是用MLE(maximum likelihood estimation)。
假设有$N$条观测序列:
每条的长度是$T_i$。比如说
对于每条观测序列都有:
所以
统计初始状态次数(多少条序列是从$i$开始的)以及状态转移次数($i$到$j$的次数):
于是
在满足$\sum_k \pi_k = 1$和$\sum_j A_{ij} = 1$的情况下maximize $\log P(\mathcal{D})$就会得到:
所以$\hat{A}$适合一行一行算。
例子:
统计一下:
所以可以得到
Hidden Markov Models
现实中很多系统的真实状态并不能直接被看到,我们只能通过观测来间接感知。
所以我们需要考虑当序列数据的真实状态看不见,只能看到带噪声的观测时,怎么建模、推断和学习参数。
比如说我们考虑一个观测飞机位置的例子:
- 真正的状态是位置、速度等物理量,是隐藏变量
- 传感器读到的是有噪声的位置,是观测变量
真实状态序列可能满足 Markov 性,但观测序列本身未必满足,所以需要 HMM。
Definition: A Hidden Markov Model (HMM) is composed of a sequence of hidden/latent variables $[Z_1,\ldots,Z_T]$ and a sequence of observed variables $[X_1,\ldots,X_T]$ such that:
- The r.v. $Z_1,\ldots,Z_T$ satisfy the Markov property:
where $P(Z_{t+1}\mid Z_t)$ are the transition probabilities.
- Distribution of $X_t$ depends only on $Z_t$:
where $P(X_{t+1}\mid Z_{t+1})$ are the emission probabilities.
也就是说当前隐藏状态只依赖上一个隐藏状态,并且当前观测状态只取决于当前的隐藏状态。
和之前一样,可以这样建模:
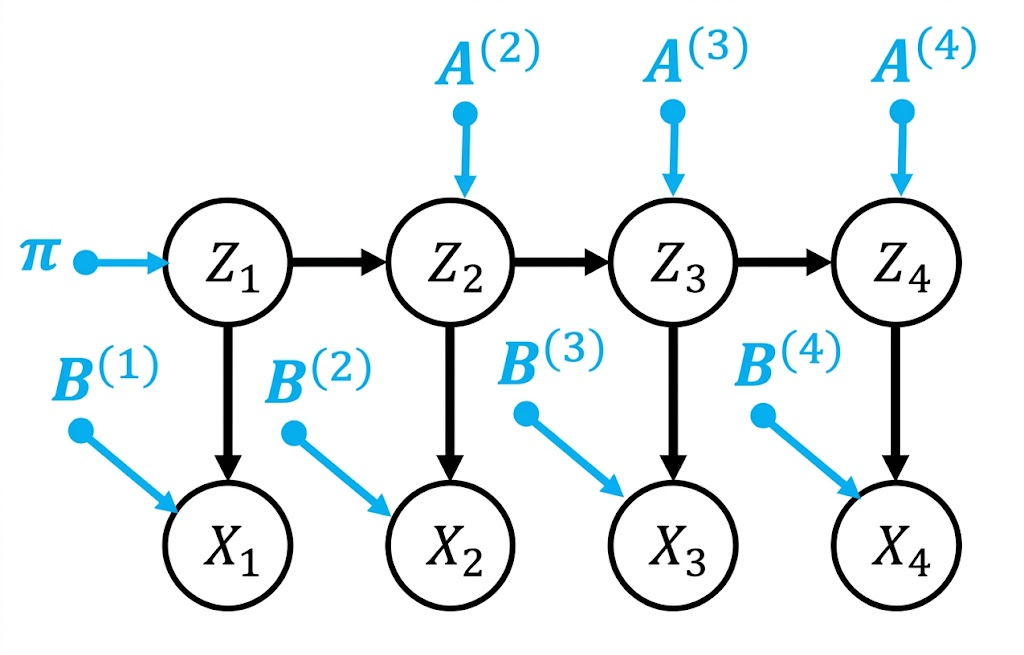
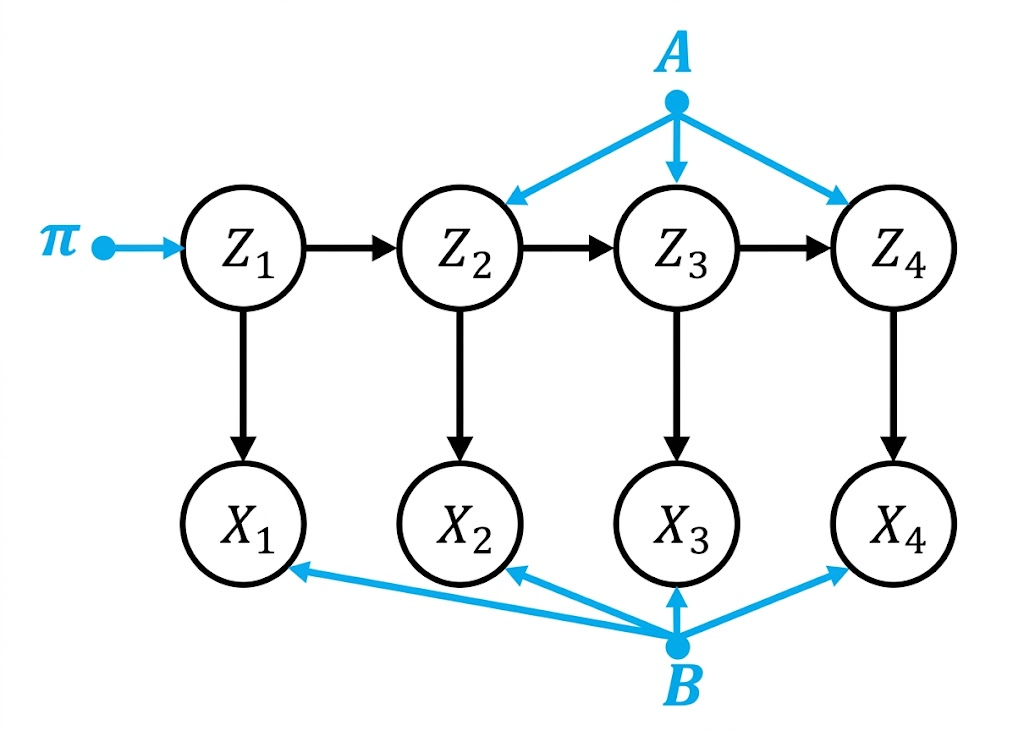
但为了降低参数数量,我们还是假设所有时间点共享一样的分布$A,B$:
在HMM中,我们一般有2种任务(都是假设已知观测数据$X_{1:T}$):
- Inference:参数($(\pi, A, B)$)已知,推导隐藏状态
- Parameter Learning:隐藏状态未知,学习模型参数
Inference
而Inference一般也分3种:
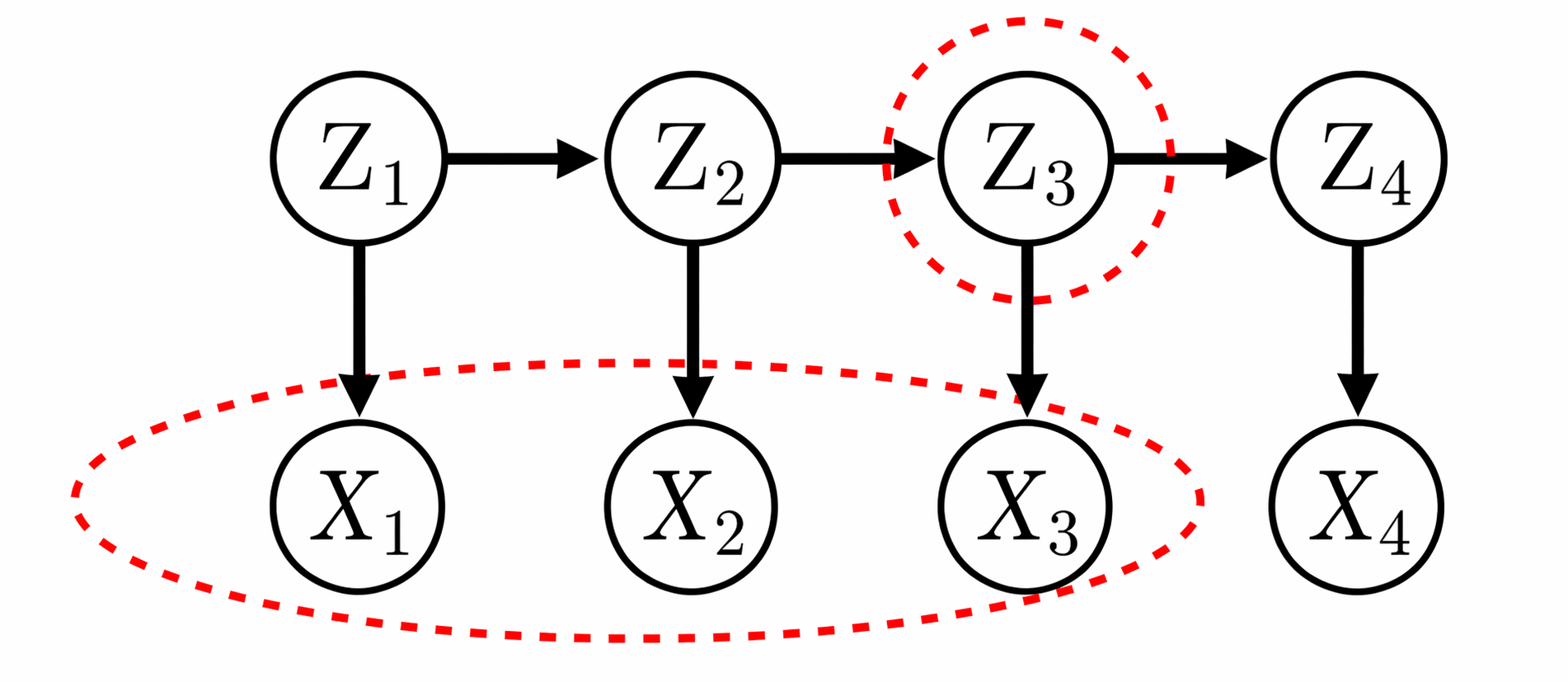
Filtering: computes $P(Z_t \mid X_{1:t} )$ online
只拥有到目前为止的所有观测信息,也就是及时判断。
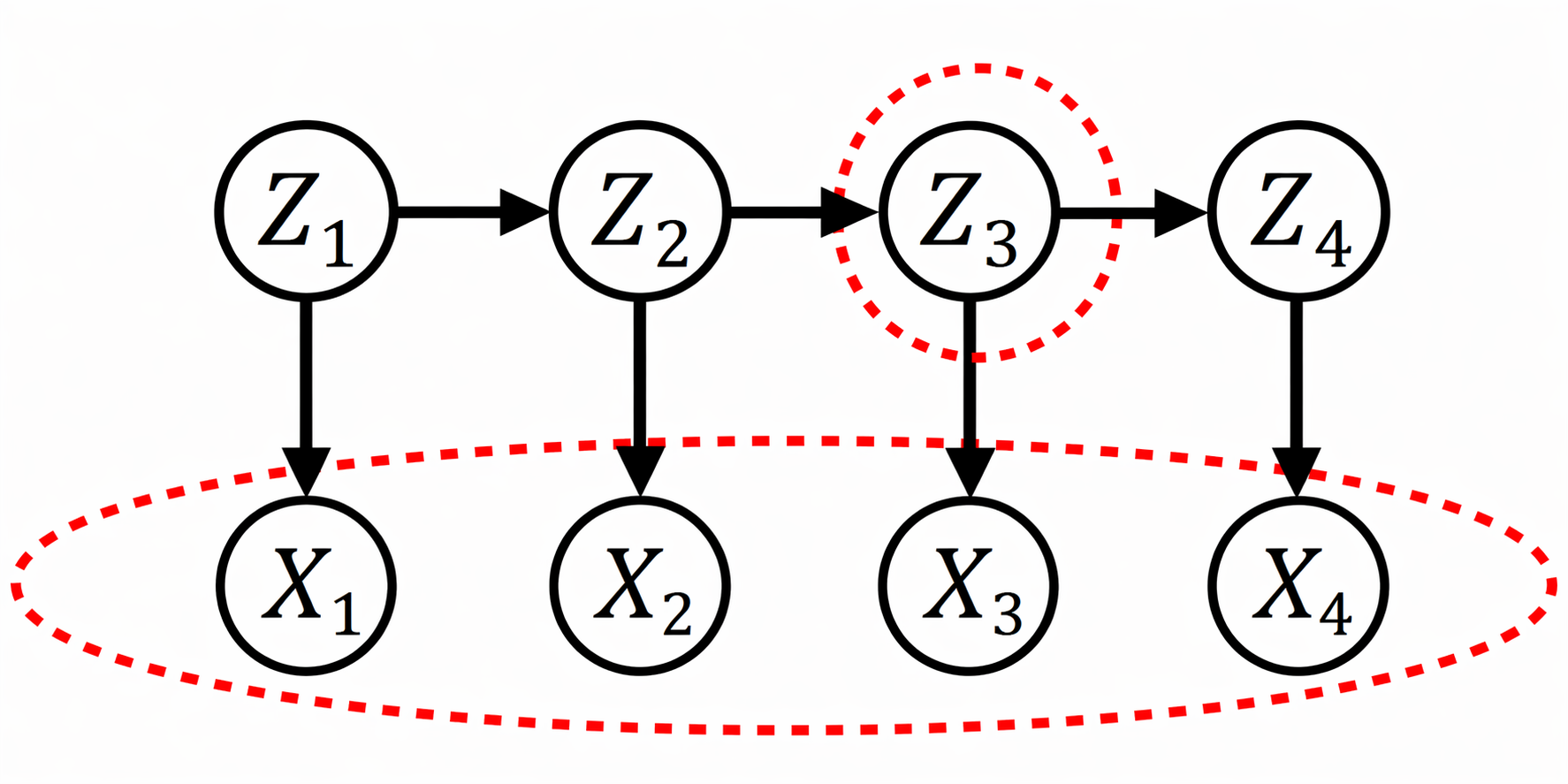
Smoothing: computes $P(Z_t \mid X_{1:T} )$ offline
拥有全部的观测信息,也就是事后回顾。
MAP inference: computes $\text{arg } \underset{Z_{1:T}}{\text{max}}P(Z_{1:T} \mid X_{1:T} )$
Filtering
computes $P(Z_t \mid X_{1:t} )$.
Forward Algorithm:
记
根据Bayes rule:
Forward Algorithm主要就分2步:
计算$\alpha_1$(initialisation):
给定$\alpha_t$,计算$\alpha_t$(recursion):
写成矩阵的话就是:
(其中$\odot$ denotes the Hadamard product:$(A \odot B)_{ij} = (A)_{ij}(B)_{ij}.$)
计算$\alpha_{1:T}$的复杂度为$O(TK^2)$。
Smoothing
computes $P(Z_t \mid X_{1:T} )$ .
Forward-Backward Algorithm:
在之前forward的基础上再定义一个$\beta$:
那么根据Bayes就有:
Backward Algorithm也分2步:
计算$\beta_T$(initialisation):
因为在$T$的时候:
$\alpha_T(k)$已经捕获了所有已知信息了,所以$\beta_T(k)$就需要是个常量。
给定$\beta_{t+1}$,计算$\beta_t$(recursion):
写成矩阵的话就是:
计算$\beta_{1:T}$的复杂度也为$O(TK^2)$。
最后计算
即可。
MAP inference
Viterbi algorithm:
注意到:
注意到每一项都只取决于$Z_t$和$Z_{t-1}$,所以我们可以把它转成一个图论里的最短路径问题:
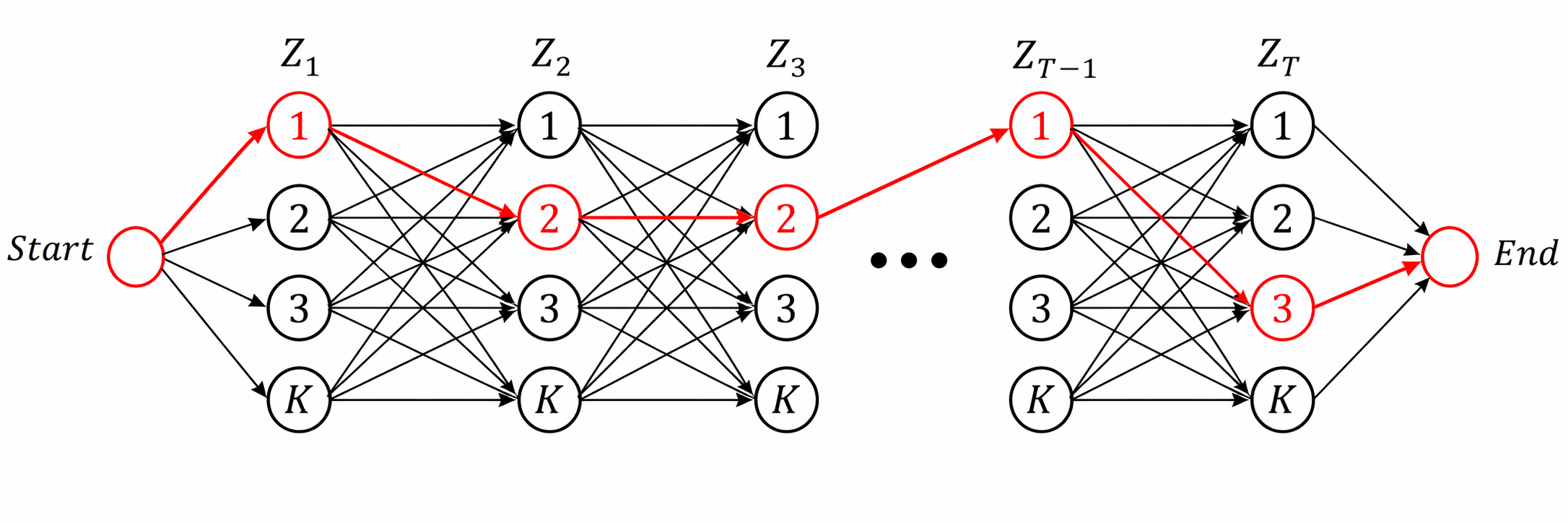
其中:
- 和start相连的边的权重:$-\log\left[ \Pr(Z_1=j)\Pr(X_1\mid Z_1=j) \right]$
- 中间层:$-\log\left[\Pr(Z_t=j\mid Z_{t-1}=i)\Pr(X_t\mid Z_t=j)\right]$
- 和start相连的边:$0$
复杂度依旧是$O(TK^2)$。
Parameter Learning
$X_{1:T}$已知,$Z_{1:T}$未知。
目标:求
也就是说虽然 $X$ 观测到了,但背后的状态序列 $Z_{1:T}$ 没看到,所以必须把所有可能的隐藏状态序列都加起来。但隐藏状态序列的可能数是指数级的,所以不能直接做。
但注意到这和GMM问题很像,所以我们考虑用EM算法求近似解。
Baum-Welch algorithm:
E step: evaluate the posterior:
其中
M step: maximize the expected joint log-likelihood
其中
Continuous Data
我们之前假设的是离散的情况:discrete time $t \in \{1,2,\ldots,T\}$ and discrete r.v.$Z_t \in \{1,2,\ldots,K\}$, $X_t \in \{1,2,\ldots,K’\}$
我们现在关注discrete time $t \in \{1,2,\ldots,T\}$, discrete r.v. $Z_t \in \{1,2,\ldots,K\}$, and continuous $X_t \in \mathbb{R}^d$:
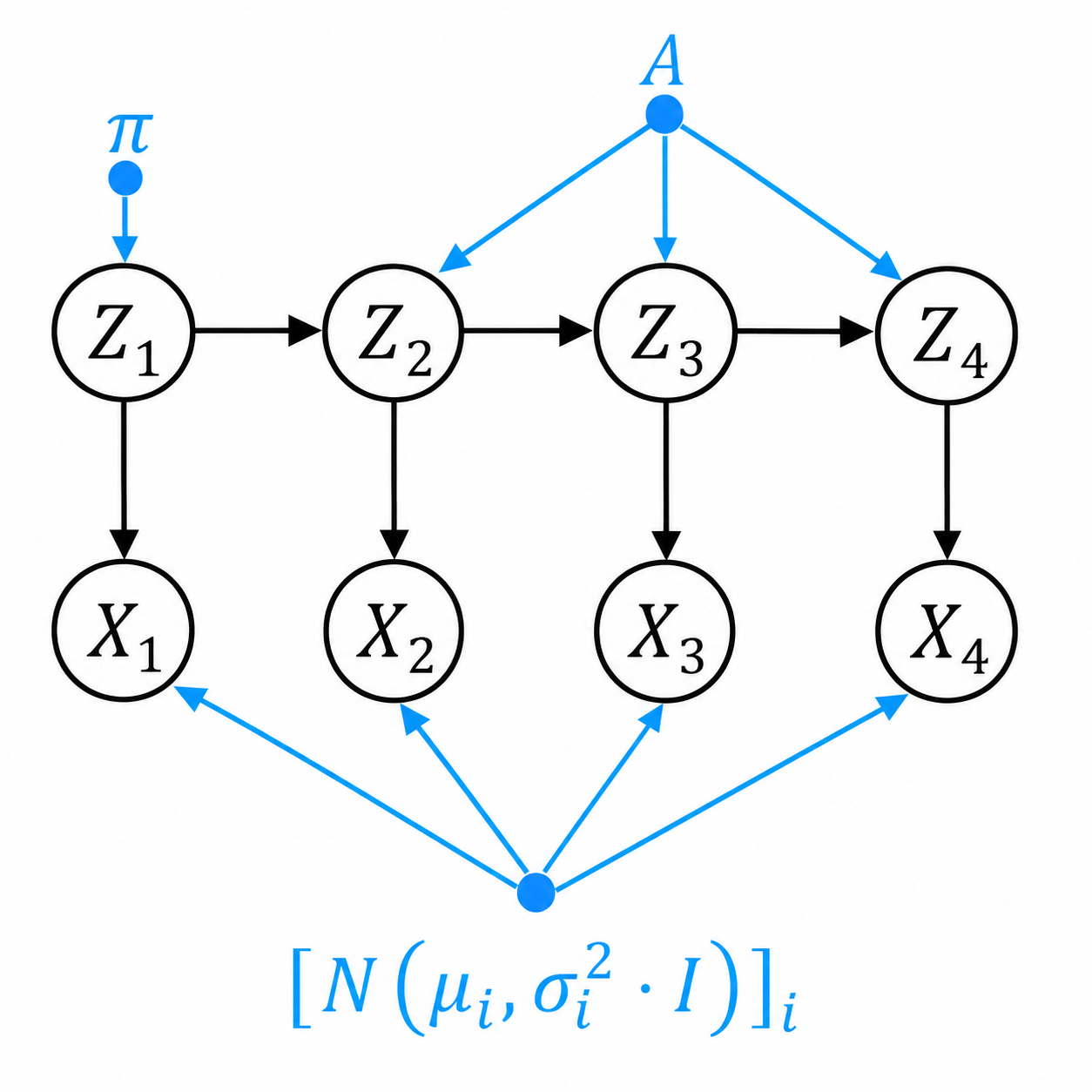
Inference部分基本不变,只需要把所有计算
的部分改成
即可。
而Parameter Learning的部分,E-Step没有变化,M-step需要一点调整:
而它的参数更新的公式:
和GMM里更新高斯参数的形式是等价/一样的。
唯一的区别就是:
- 在 GMM 里,不同观测样本$X_t$是独立的(independent)
- 在 HMM 里,观测 $X_t$ 在给定隐藏状态之后是条件独立的(conditional independent given $Z$)
Neural Network Approches
Word Vectors
由于神经网络不能直接处理单词,所以我们需要先把词表示成向量,方便后续计算处理。
最简单的想法就是one-hot encoding:假设有个单词数量为n的单词表,把每个单词转成一个维度为n的向量(其中有且仅有一项等于1)。但它有三个问题:维度高、稀疏、假设词之间相互独立。
于是就引出了 word vectors / embeddings:相似词的向量应该接近,比如 “hotel” 和 “motel”,”man”和”woman”,”walking”和”walked”。这基于分布式假设:出现在相似上下文中的词,通常有相似含义。
有2种常见的获取word vectors的方法:
1. Co-occurence Matrix + SVD:
这个方法偏统计。它的初始想法很直观:一个词的含义可以通过“它经常和哪些词一起出现”来表示。
先统计一个词附近出现哪些词,得到一个co-occurrence matrix。然后再用SVD把高维稀疏向量压缩成低维稠密向量。
优点是相似的单词会得到相似的向量。
缺点是计算慢,而且新词不好加入。
2. Word2Vec
这种方法偏预测。
先设计一个预测任务,然后用神经网络学习词向量。
来看2个经典模型:
1. CBOW (Continuous Bag-of-Words):
给定一个词周围的上下文词(window),预测中间词。
但是这种方法对稀有词不太好,因为稀有词出现次数非常少,模型很少有机会把它作为要预测的目标词,所以不容易学好它的向量。
2. Skip-gram:
给定中心词,预测它周围的上下文词。
它对稀有词更友好(可以这样理解:如果一个 rare word 出现了,模型会强迫自己用这个 rare word 去预测它的上下文。这样模型必须理解这个 rare word 通常出现在什么环境中,因此更容易学到它的含义。),但训练起来也会更慢。
来看一下具体的结构:
假设词表大小是$N$,并且每个词一开始用one-hot vector来表示。
Embedding则是通过一个矩阵$U \in \mathbb{R}^{N \times D}$来实现的。由于所有输入都是one-hot vector,所有相当于$U$的每一行都是对应一个单词的embedding结果的。
在此基础上还需要一个矩阵$V \in \mathbb{R}^{D \times N}$,用来把中心词 embedding 转换成对整个词表的预测分数。最后再套上softmax就会得到一个上下文单词的概率分布。
也就是整体流程是这样的:
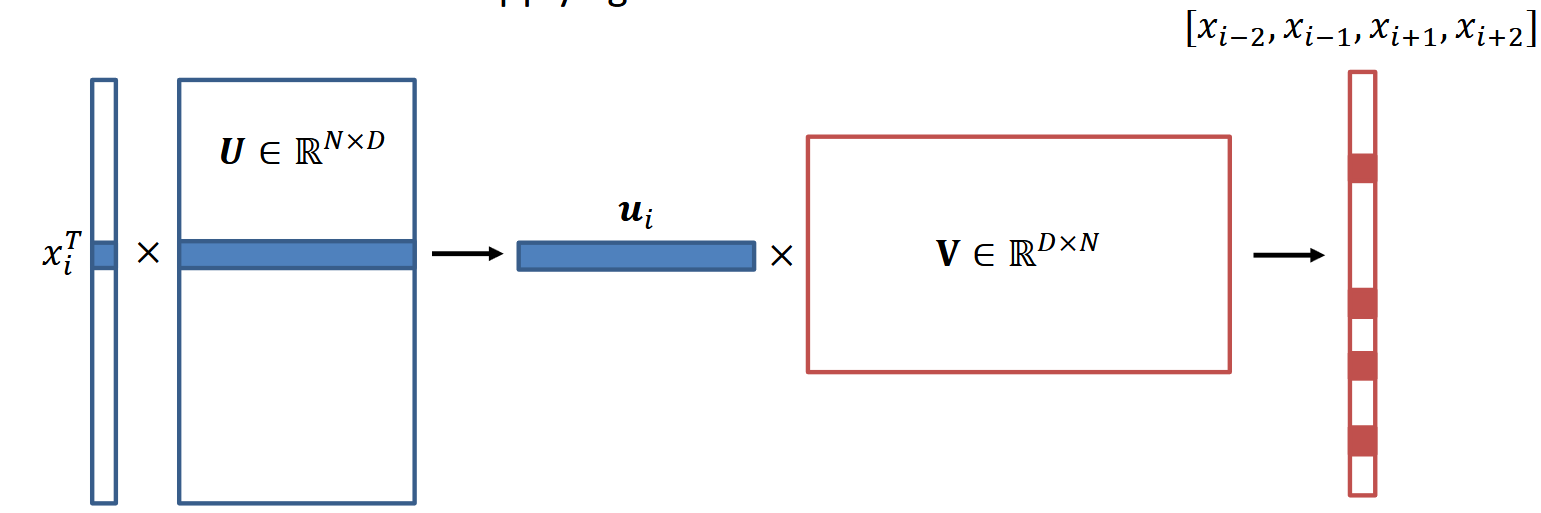
假设$S=[x_{i-l},\ldots,x_{i-1},x_{i+1},\ldots,x_{i+l}]$是当前$x_i$的大小为$l$的window,$\theta = (U,V)$为模型参数,那么我们的训练目标就是最大化这个期望值:
其中
但是注意到,softmax的形式是:
为了计算这个分母我们需要遍历整个单词表,当单词表很大的时候会非常低效。
所以可以用negative sampling技巧:我们不再把问题看成从整个词表中预测正确上下文词,而是把它变成一个二分类问题:判断一个词对是不是真实的上下文关系。
利用(最小化)这个Loss来训练模型:
并且用sigmoid代替softmax:
如果两个词经常一起出现,它们的向量点积应该大,sigmoid 后接近 1。
如果两个词很少一起出现,它们的向量点积应该小,sigmoid 后接近 0。
RNNs
我们刚才看了如何处理单个单词。但我们该怎么处理一整句话、一个音频片段、一个时间序列呢?尤其是它们的长度都各不相同。
比如说当我们希望它接收输入:
,并且输出
答案就是Recurrent Neural Networks (RNNs)。它的基本想法是用一个 hidden state 来总结到目前为止读过的序列信息。
RNN可以处理多种任务:
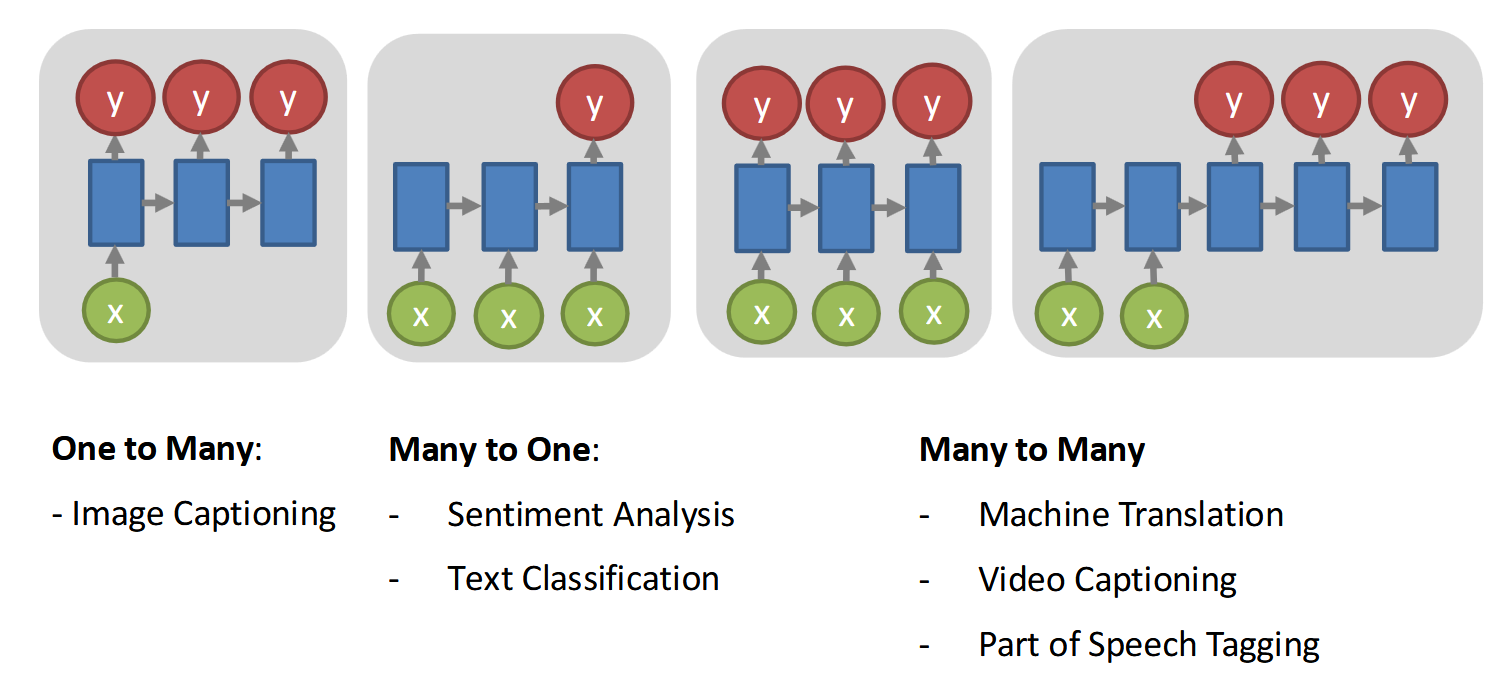
来看正式的定义:
假设输入是$\{x^{(1)},\ldots,x^{(T)}\}$,并且输出$\{y^{(1)},\ldots,y^{(T)}\}$。我们现在希望知道
的概率分布。
所以我们用 $h^{(t-1)}$表示/记录$\{x^{(1)},\ldots,x^{(t-1)}\}$的信息。
具体的更新公式:
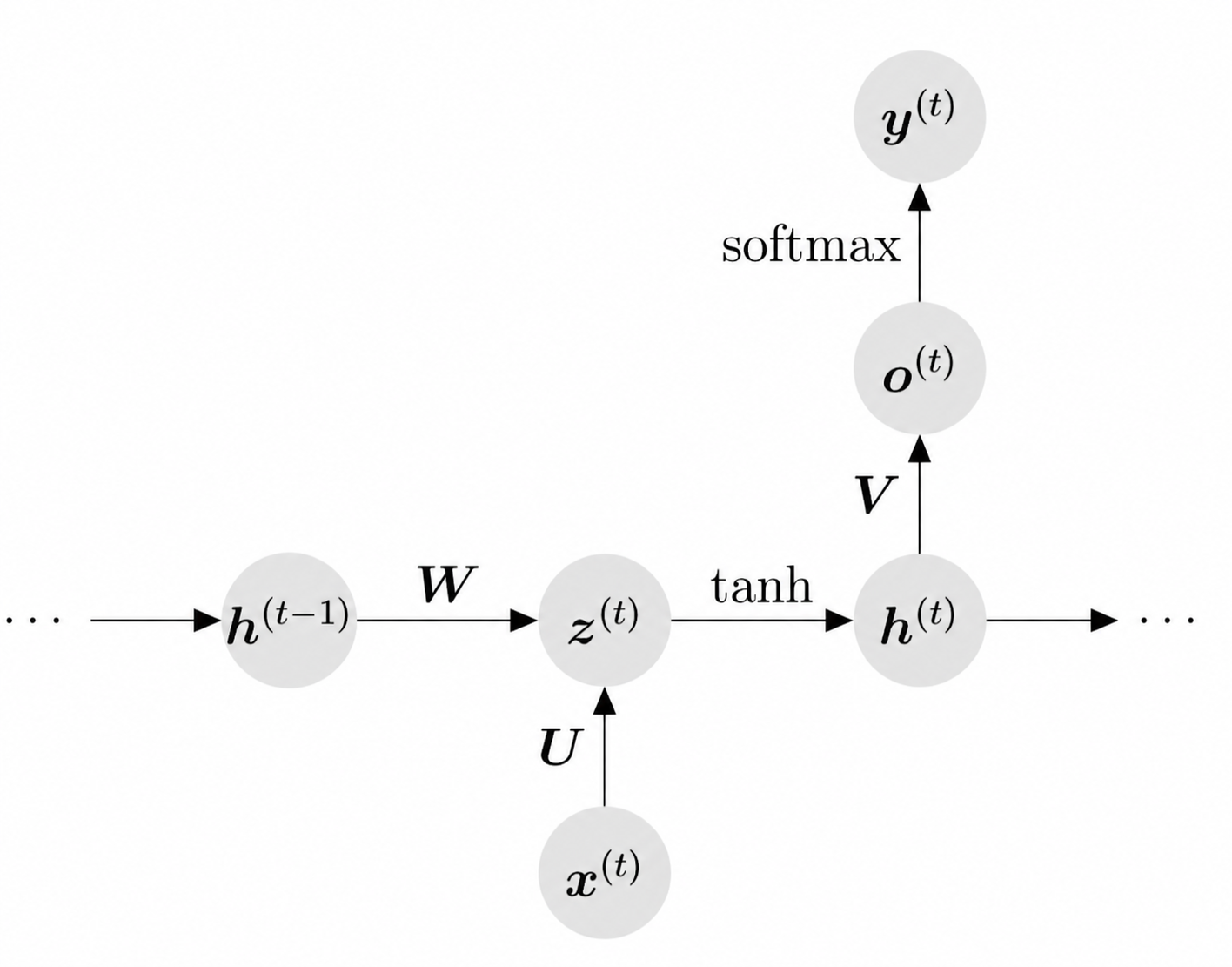
训练的时候关注negative log-likelihood:
当我们将RNN展开(unrolling):
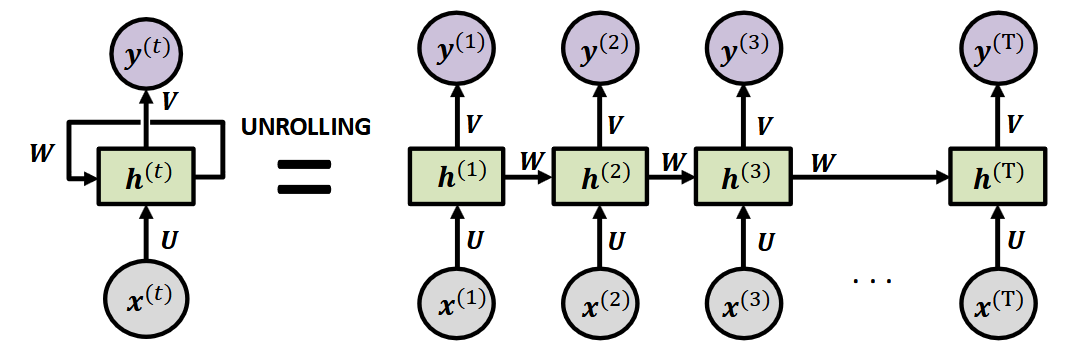
就会发现它像一个很深的神经网络,所以可以用反向传播训练。
假设真实标签$y^{(t)}$用的是one-hot label(即其中只有一位等于1,其余位均等于0),$\hat{y}_c^{(t)}$为每轮训练时得到的softmax之后的分布,那么$L^{(t)}$就可以写成
来计算它的导数。
先看$\frac{\partial L^{(t)}}{\partial o_i^{(t)}}$:
所以
再来看$\frac{\partial L^{(t)}}{\partial V^{(t)}}$
类似的有:
但注意到里面用到的$h^{(t)}$是递归定义的:
所以当计算$\frac{\partial L}{\partial h^{(t)}}$时:
其中
$W$的连乘会导致这个梯度消失或者爆炸(vanish/explode),进而会导致RNN无法有效地更新/学习到信息。
为了解决这个问题我们需要完善目前的架构。
GRU (Gated Recurrent Unit)
核心思想:不是每一步都完全覆盖 hidden state,而是引入gate来控制保留多少旧信息以及接受多少新信息。
(有点类似residual NN的idea。)
更新公式:
其中$\odot$为elemente-wise product。
update gate $z^{(t)}$会决定最后是保留更多的previous state还是新的candidate state。
reset gate $r^{(t)}$则是决定计算新的candidate state时,参考多少之前的hidden state的信息。
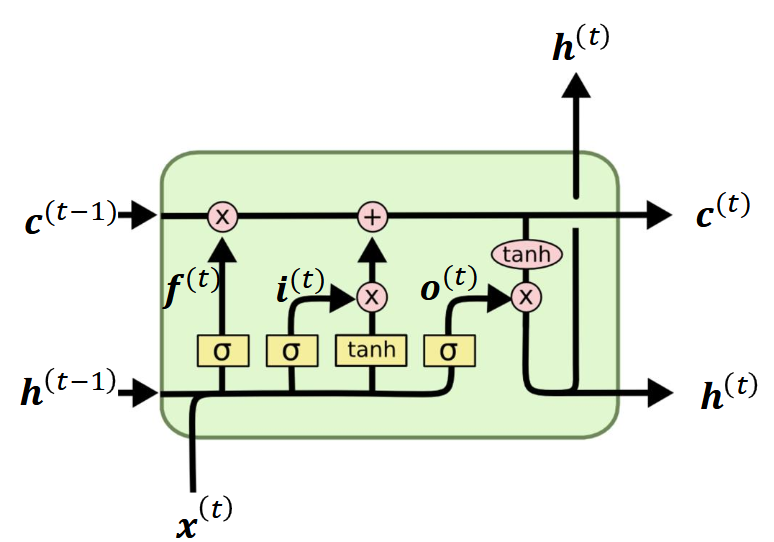
LSTM (Long Short-Term Memory)
更加强力的架构。我们在hidden state $h^{(t)}$的基础上再引入一个新的cell state $c^{(t)}$。
Forget gate:
决定保留多少之前的cell state信息。
Input gate:
决定将多少新信息写入新的cell state。
Output gate:
决定更新hidden state时参考多少cell state的信息。
Update cell state:
Update hidden state using cell state:
Non-Recurrent Modesl (ConvNets, Transformer)
RNN的结构:
会带来2个问题:
- 无法并行计算,因为每个hidden state都依赖前面的state
- 无法保证长期
但有些序列任务其实不一定需要完整历史,只需要一个固定范围的过去信息。
ConvNets/WaveNet
连续函数上的卷积是:
在图像处理中,我们常见2D(离散)卷积:
因为sequence是1维的,所以我们可以用1D的ConvNets。
假设有一个长度为 $3$ 的卷积核:
对于序列:
普通1D卷积会在序列上滑动窗口。例如某个输出可能是:
这和之前的autoregressive model非常像,但ConvNet可以叠很多层、加非线性,从而学习更复杂的模式。
WaveNet是一个用 1D ConvNet 建模 speech / raw audio 的模型。它有两个关键设计:
Causal convolution
确保卷积只能看到之前的信息。
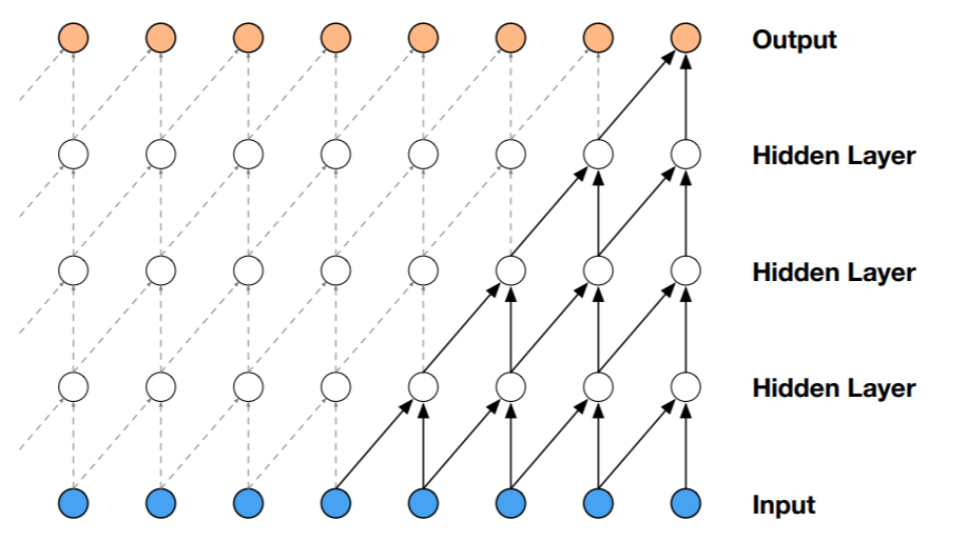
Dilated convolution
(在序列模型里,某个输出 $y_t$ 能看到多少个输入位置,就叫它的receptive field。)
普通卷积看连续相邻输入:
而 dilated convolution 会“隔着看”。
比如 dilation $=2$ 时,可能看:
dilation $=4$ 时,看:
WaveNet常用的做法是每一层dilation翻倍:
这样receptive field会随着层数指数级增长。这样便可以只用少数层就能覆盖很长历史。
Transformer&Attention
Transformer 是非循环模型。它不像RNN那样一步一步更新hidden state,也不像ConvNet那样只看固定窗口,而是用attention让每个token可以直接和其他token交互。
对于当前位置 $x_i$,模型会学习
- 应该关注序列中哪些位置 $x_j$?
- 每个位置关注多少?(权重 weight)
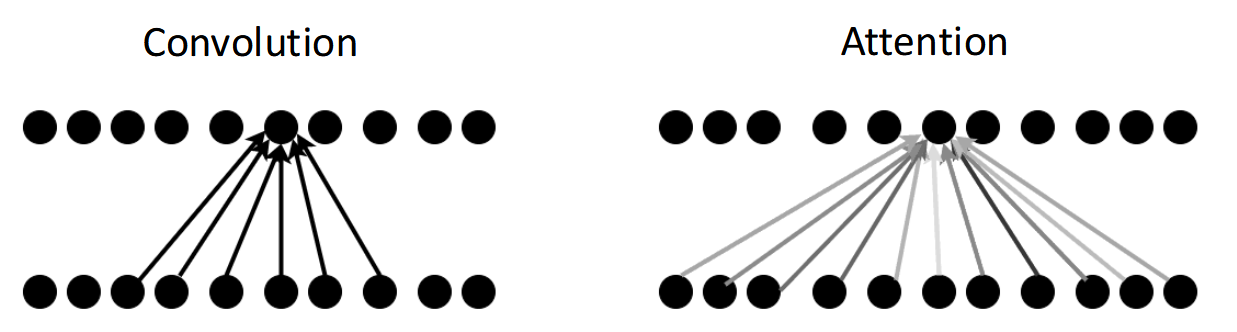
(attension中不同深浅的颜色代表不同的重要程度/权重)
Attension有三个核心概念:
也就是:
- Query
- Key
- Value
可以用一个比喻理解:
Query:我在找什么?
Key:我有什么特征,可以被别人匹配?
Value:如果别人关注我,我实际提供什么信息?
attension的具体计算过程:
第一步,计算 $x_i$ 对每个 $x_j$ 的分数:
分数越高,表示$x_i$越应该关注$x_j$。
第二步,对这些分数做 scaling 和 softmax:
这里$\alpha_{ij}$是attention weight,表示位置$i$对位置$j$的关注程度。
第三步,用这些权重加权value:
得到当前位置的新表示$z_i$。
用矩阵的写法则是:
其中$QK^T$是 $n \times n$ 的矩阵。
由于Attention本身无法察觉顺序,所以我们需要加入Positional Encoding,也就是给每个token的embedding加上或拼接一个表示位置的向量。
与RNN相比,Transformer有一个非常重要的特性:训练时可以并行。RNN必须按顺序处理每个token,因为每一步的输出都依赖上一步的隐藏状态;而Transformer没有这种时序依赖,可以一次性把整个序列喂进去同时计算。
但这里有个问题——语言模型在预测某个token时,不应该”提前看到”它后面的内容,否则训练就失去意义了。解决办法是使用causal mask(因果掩码):在注意力计算中,将每个位置右边的部分遮住,强制模型只能关注当前及之前的token。
以训练句子”I like this movie”为例:
I只能看Ilike只能看I, likethis只能看I, like, thismovie只能看I, like, this, movie
这四个位置的计算在训练时是同时进行的,效率远高于RNN的逐步处理。
不过,这种并行性只存在于训练阶段。推理时,由于每个新token都依赖前面已生成的结果,模型仍然只能一个token一个token地顺序输出。
Stuctured State Space Models
先来对比一下前面的RNN和Transformer架构:
| Training 训练 | Inference 推理 | |
|---|---|---|
| RNN | 慢 | 快(只需要根据当前的hidden state来计算下一个hidden state) |
| Transformer | 快(可并行) | 慢(复杂度差不多是序列长度的平方) |
那么有没有办法可以设计一个架构同时拥有它们2个的优点呢?
State-space model
考虑输入$u_k \in \mathbb{R}$,输出$y_k \in \mathbb{R}$,以及$\bar{A}\in\mathbb{R}^{N\times N}, \bar{B}\in\mathbb{R}^{N\times 1}, \bar{C}\in\mathbb{R}^{1\times N}$。
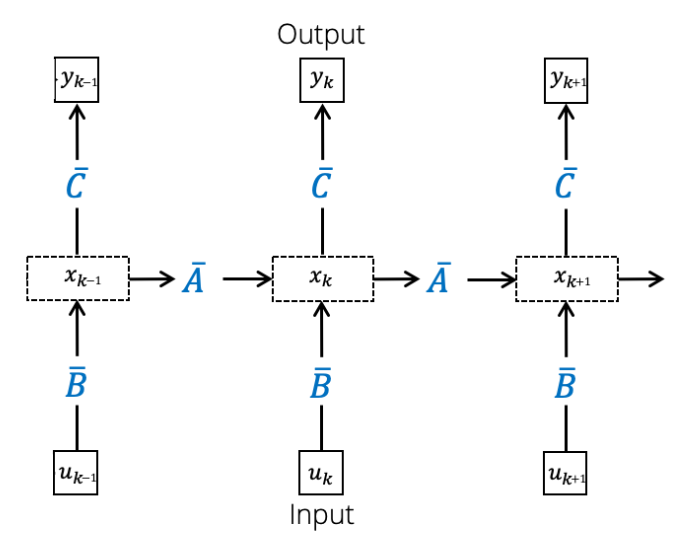
注意到$y_k$可以写成
等价于$\bar{K}$和$u$的卷积:
重点来了,目前的这个架构有着2种等价的形式,所以同时拥有着2种形式的优势:
递归
推理时很高效,复杂度为线性。
卷积
训练时可以并行,因为整段序列的卷积可以一次算。
但是光这样还不够,因为在计算$\bar{K}$时实际上需要计算$\bar{A}^{L-1}$,复杂度依旧很高。
所以我们可以挑选合适的$\bar{A}$的结构来确保复杂度不会太高。
S4 model
S4 (Structed State Space for Sequences) model。
Event Data Modeling
之前考虑的都是数列的值,也就是$x_{t_1},x_{t_2},…$。我们现在来考虑时间(也就是index本身)。
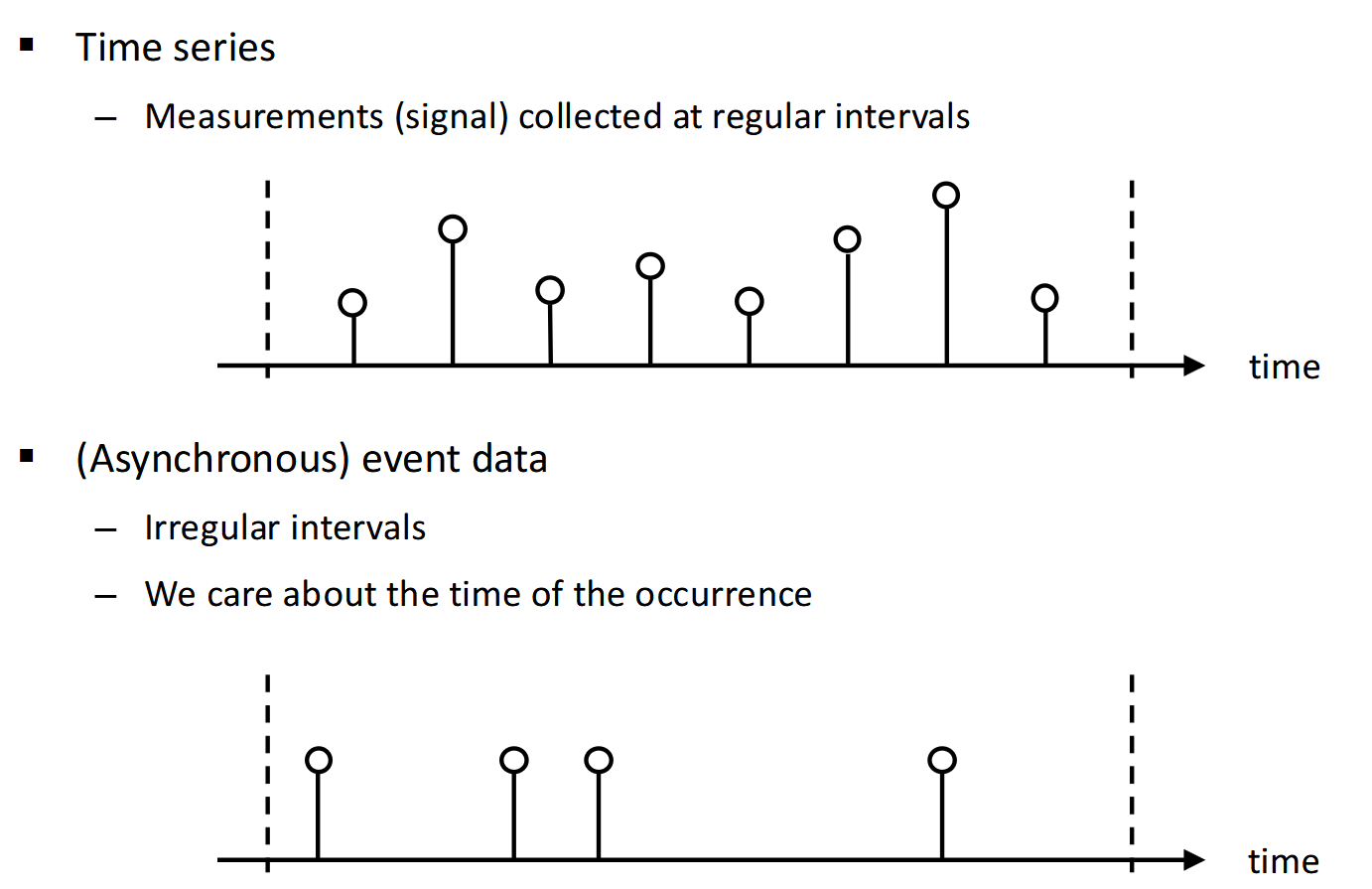
也就是我们现在有一些event,然后我们希望预测下一个event会在什么是发生。
Definition: Temporal Point Processes (TPP) are a class of probabilistic models that describe the distribution of discrete event sequences in continuous time.
TPP defines a generative model for variable-length sequences
on the interval $[0,T]$, with likelihood function $p(\{ t_1,…,t_N \})$.

记历史事件为$\mathcal{H}(t) = \{ t_j < t \} = \{t_j \mid t_j < t \}$。那么模型描述的conditional density(下一个事件发生的时间概率分布)就是
并且不难注意到:
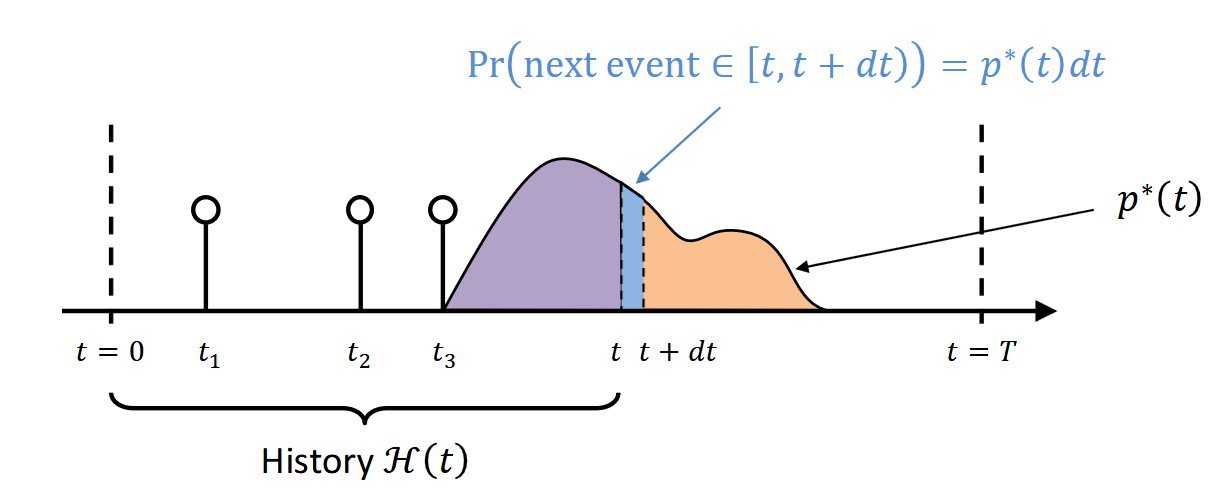
(严格来讲图里的$\mathcal{H}(t)$应该只画到$t_3$那里。)
CDF:
为下一个时间发生在$[t_{i-1},t)$的概率。其中$t_{i-1}$为$t$之前的最后一个事件(的时间)。
Survival function:
为下一个时间不发生在时间$t$之前的概率,或者说下一个时间发生在$t$之后的概率。
conditional intensity function:
在已知$[t_{i-1},t)$中没有发生事件的情况下在$[t,t+dt)$中发生事件的概率。
($\int_t^{t+dt} p^(t)dt$有时候会被省略成$p^(t)dt$。)
也就是:
这几个函数之间的关系:
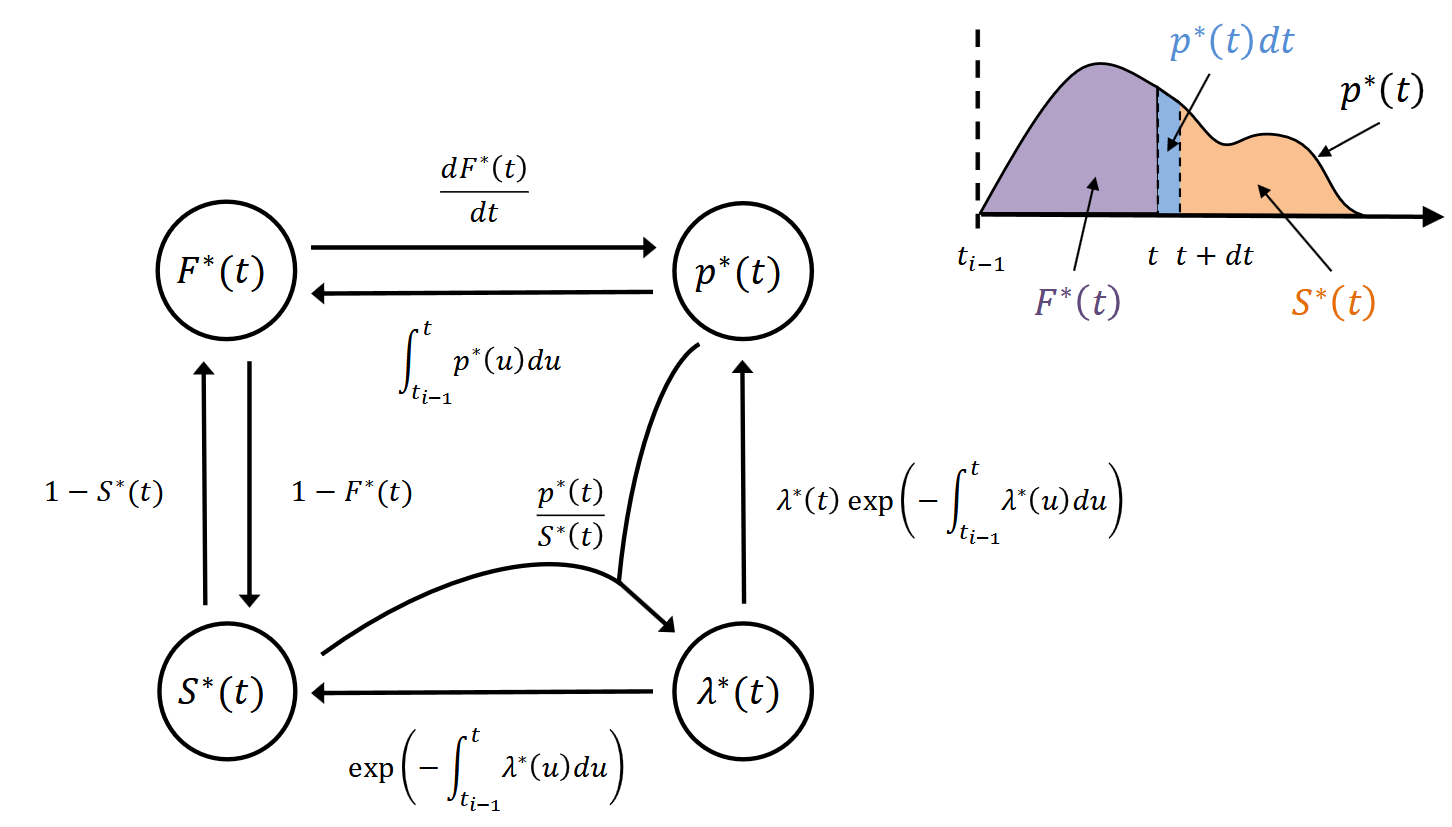
那么该怎么计算一个realization的概率呢?
Selected TPP Models
用$\lambda^*(t)$建模
如果用$\lambda^*(t)$来定义模型,有几个好处:
- 容易设计具有特定行为的模型,例如全局趋势、爆发性、排斥性。
- 强度函数比较可解释。
- 不同过程可以组合,例如两个强度相加。
- 采样可以更高效。
Homogeneous Poisson Process(HPP)
假设强度恒定:
服从指数分布:
记$\tau_i = t-t_{i-1}$,那么
模拟HPP很简单:不断从指数分布采样间隔 $\tau_i$,然后累加得到事件时间:
1 | arrival_times = [] |
复习一下一个定理:
Theorem (Inverse CDF Transform):
设
设 $F:\mathbb{R}\to[0,1]$ 是某个随机变量的累积分布函数(CDF),定义广义反函数,即quantile function:
令
则 $X$ 的累积分布函数为 $F$,也就是说:
换句话说:
所以取样(Sampling)的话就很简单:
取$u \sim \operatorname{Uniform}(0,1)$,那么
HPP 适合描述“事件均匀随机发生”的场景,但表达力很弱。
Inhomogeneous Poisson Process (IPP)
IPP 允许强度随时间变化:
不依赖历史,但可以捕捉全局趋势。
而事件的数量满足Poisson分布:
假如有2个IPP的intensities是$g(t)$和$h(t)$,那么它们的和也是IPP并且intensity就是$g(t) + h(t)$。
Hawkes Process
也叫自激励过程(self-exciting process)。它的intensity等于
其中
被叫做Triggering kernel。并且参数$\mu, \alpha, \omega \geq 0$。是依赖历史记录的。
Hawkes Process 的核心特点是 self-exciting。一个事件发生后,会暂时提高后续事件的发生概率,然后这个影响逐渐衰减。因此它适合建模 bursty、clustered 的现象,比如社交媒体转发、地震余震、金融市场连锁交易、用户连续发消息等。
参数估计/学习
最大化训练集中所有序列的 log-likelihood:
其中
建模$p^*(t)$
因为用$\lambda^(t)$建模的话计算log-likelihood部分需要算积分,复杂的情况下会无法计算。所以我们也可以直接用RNN建模$p^(t)$。
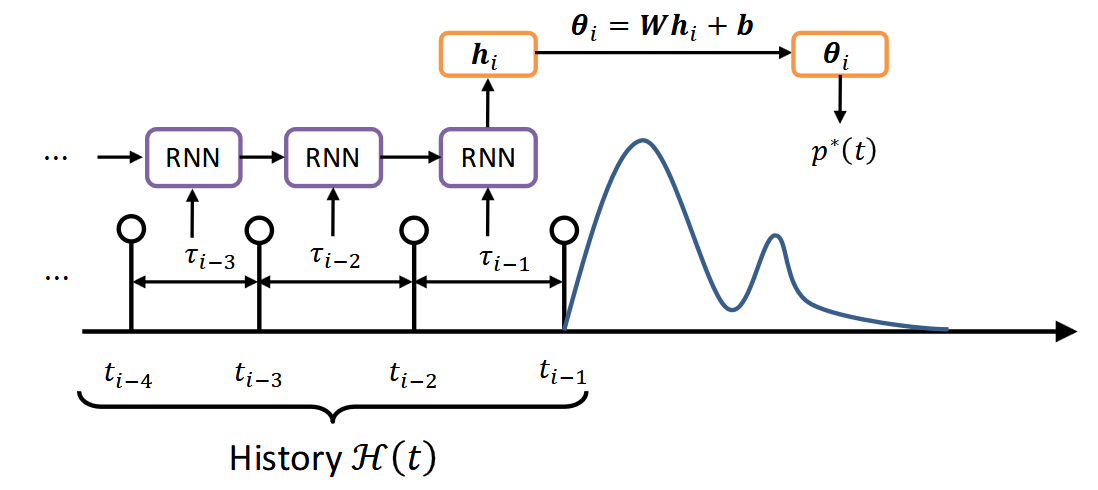
利用RNN来记录evnt时间差的历史,并基于这个历史得到$p^*(t)$的分布。
但这样autoregressive TPP还是有几个(和之前RNN类似的)问题:
第一,误差累积。预测下一个事件错了,后面基于它继续预测会越错越远。
第二,计算复杂度高,因为要一步步生成事件。
第三,难以建模长距离依赖,尤其是很早以前的事件对很久之后事件的影响。
再来看个变种:ADD and THIN: Diffusion for Temporal Point Processes。
Noising 阶段:
从真实数据样本 $\mathbf{t}^{(0)}\sim \lambda_0$ 开始,每一步做两件事:
- Thin:随机删除一部分已有事件。
- Add:从 HPP 添加一些噪声事件。
经过很多步后,原始事件序列逐渐变成一个简单的 HPP 噪声分布:
Denoising 阶段:
从噪声事件序列开始,逐步采样回更干净的事件序列,最终恢复数据分布: